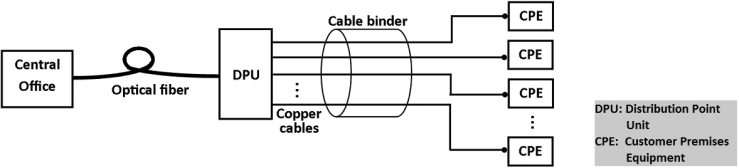
VDSL/VDSL2 are digital subscriber lines (DSL) that provide high bit rate and thus fast data transmission over wired telephone lines. These technologies use twisted pair of copper wires or coaxial cables for transmission. The greatest source of impediment in the DSL lines is crosstalk stemming from other DSL lines in the same cable binder. But this crosstalk is cancelled using vectoring which employs a joint signal processing of all user signals. The other major source of obstruction in these wired lines is noise. Impulse noise is generally a high power intermittent noise coupling electromagnetically into the cable binder with the common sources of such noises at the customer premises equipment (CPE) being PLC modems and household appliances like washing machine, treadmill etc. Impulse noise can be classified into two types: Repetitive Electrical Impulse Noise (REIN) and Prolonged Electrical Impulse Noise (PEIN). Reducing the disturbance caused by such noises is necessary for increasing the throughput of the VDSL systems.
The twisted pair has two modes for transmission: the common mode (CM) and the differential mode (DM). VDSL uses the differential mode for data transmission due to its robustness to the electromagnetically (EM) coupled noise. The EM coupled noises like crosstalk and impulse noises couple onto the twisted pair as common mode signals and a fraction of the coupled noise leaks into the differential mode due to cable imbalances in the twisted pair thus hampering the transmission of useful data signal. Thus, due to the leakage or coupling of signals between the common and differential mode, the CM and DM sensors exhibit a correlation. If the correlation can be estimated, the CM signal can be used to cancel the impulse noise in the DM.
The biggest challenge in impulse noise cancellation is that the estimation of the correlation or the coupling function has to be done in presence of high powered data signal during show time as the coupling is dependent on the noise source. Thus, the estimation of CM-DM coupling needs a large number of DMT symbols to average out the stronger data signal. In case of PEIN/SHINE noises, which are transient in nature, this cancellation needs to be faster i.e. within a few symbols.
While there have been several approaches which attempt to cancel out impulse noise based on CM sensor, they have slow convergence in presence of data signal and rely on the repetitive nature of the noise. Therefore, they are not suitable for transient noise cancellation. To combat this shortcoming, we address the issue in a decision directed way which can give faster convergence for near optimal cancellation of impulse noise useful for transient as well as repetitive noise.


 are to be estimated. That is, the L unknowns are to be found out from this one equation making this problem underdetermined with infinite solutions. To recover the exact sources from this infinite set of solutions, one needs some prior information about the sources.
are to be estimated. That is, the L unknowns are to be found out from this one equation making this problem underdetermined with infinite solutions. To recover the exact sources from this infinite set of solutions, one needs some prior information about the sources.
